3 Introducing a New, Free, and Independent Method for Standardised, Reproducible and Reliable Analyses of Antimicrobial Resistance Data
In preparation
Berends MS 1,2, Luz CF 2, Sinha BNM 2, Glasner C 2‡, Friedrich AW 2‡
- Certe Medical Diagnostics & Advice Foundation, Groningen, the Netherlands
- University of Groningen, University Medical Center Groningen, Department of Medical Microbiology & Infection Control, Groningen, the Netherlands
‡ These authors contributed equally
Abstract
As the burden of antimicrobial resistance (AMR) is continuously increasing, reliable and reproducible data and data analysis are of utmost importance. Conducting AMR data analysis is challenging since it requires (1) a thorough understanding of (clinical) epidemiology; (2) expertise in (clinical) microbiology and infectious diseases; (3) experience in microbiological data analysis; (4) availability of reference data, such as the biological taxonomy of microorganisms and defined daily doses (DDD) for antimicrobials; and (5) availability of (inter-)national guidelines and software methods to apply them. Furthermore, data stored in laboratory information systems lack the right structure, (inter-) national guidelines for interpreting raw laboratory test results cannot be easily applied, and scientifically reliable reference data about microorganisms and antimicrobial agents are not readily available. To fill this gap, we developed a free, independent, and open-source software solution to cover all those aspects of working with AMR data. The AMR package for R enables AMR data analysis for research and clinical workflows alike. Through an online survey package users reported more reproducibility of analysis results (83%), more reliable outcomes of AMR analyses (72%), and new or improved insight into AMR patterns (61%). The AMR package was also used to support clinical decision-making (44%) and for clinical research (28%). Our first insights into the usage and the usability of the AMR package confirm that this package is fulfilling its intended aim, as regional, national, and international organisations already use the package to support clinical decision-making in infection management. The flexible open-source design also enables rapid integration of updated guidelines (e.g., new EUCAST breakpoints) and setting-specific adaptations are encouraged. Together, the AMR package for R can thus empower any specialist in the field working with AMR data by providing a comprehensive toolbox of solutions for AMR data analyses.
3.1 Background
As the burden of antimicrobial resistance (AMR) is continuously increasing, surveillance programs with reliable and reproducible data and data analysis methods are of utmost importance for controlling and streamlining efforts to curb AMR [1,2]. To guide these efforts and to support clinical decision-making and infection-control interventions, AMR data analysis has to be conducted in a clinically and epidemiologically sensible way [3]. Conducting AMR data analysis is challenging since it requires (1) a thorough understanding of (clinical) epidemiology; (2) expertise in (clinical) microbiology and infectious diseases; (3) experience in microbiological data analysis; (4) availability of reference data, such as the biological taxonomy of microorganisms and defined daily doses (DDD) for antimicrobials; and (5) availability of (inter-)national guidelines and software methods to apply them.
Moreover, AMR data analysis is often also hindered by three key aspects. Firstly, data stored in microbiological laboratory information systems (LIS) are typically not readily suitable for (epidemiological) data analyses. LIS were initially designed to fit result registration and billing purposes rather than AMR data analysis. Consequently, fundamental requirements for (epidemiological) data analyses are often lacking, such as isolate selection criteria, phenotypic determination of (multi-)drug resistance, and the ability to extract data for analysis in an automated, structured, fast, and reliable way. Moreover, data analyses that require data from multiple LIS sources (e.g., in multi-centre studies) face major barriers in data aggregation which, to the best of our knowledge, cannot be solved by currently available commercial software solutions. Besides, as applications of artificial intelligence are expected of being increasingly developed in the coming years, also in clinical microbiology, microbiological data technologies and structures need to become compatible for these future applications.
Secondly, AMR data analysis depends on (inter-)national standards and guidelines for the interpretation of raw laboratory measurements and the reporting of AMR results. In Europe, guidelines from the European Committee on Antimicrobial Susceptibility Testing (EUCAST) are the predominantly implemented set of rules in clinical microbiological laboratories [4,5]. LIS need to be well-maintained to be able to integrate continuous guideline updates. In our experience, this maintenance can often not be guaranteed and depends on the availability of local or external software support services. This is further hindered by the current distribution of manually formatted guidelines in Microsoft Excel and Portable Document Format (PDF) formats that are not often readily machine-readable. LIS maintainers, in collaboration with clinical staff, are therefore forced to manually implement updated guidelines which can be time-consuming and error-prone
Thirdly, reliable AMR data analysis depends on taxonomic reference data to interpret raw LIS data using AMR interpretation guidelines, such as EUCAST Expert Rules and EUCAST Clinical Breakpoints [5,6]. Unfortunately, typical LIS contain local, static taxonomic data. We found that these data are often poorly maintained. We collected the taxonomic names of bacteria used in clinical reports from seven different public health institutions in the Netherlands which cover microbiological diagnostics in hospitals and primary care for 15% of the total Dutch population. The taxonomic names were compared to publicly available and authoritative reference databases; the Catalogue of Life and the List of Prokaryotic names with Standing in Nomenclature (LPSN, previously known as the Deutsche Sammlung von Mikroorganismen und Zellkulturen, DSMZ) [7,8]. We found that all participating institutions reported taxonomic names in clinical reports that did not match current taxonomic standards according to reference databases. For example, Enterobacter aerogenes and Enterobacter massiliensis were renamed Klebsiella aerogenes and Metakosakonia massiliensis respectively in 2017 [9,10]. LIS that are not kept up to date are consequently not entirely compatible with recent interpretation guidelines. Given that AMR guidelines are strongly based on the microbial taxonomy (some rules only apply to a specific genus, other rules apply to a specific family) it is crucial that this information is correct and kept up to date. In the studied institutions, the lag between the reported taxonomic names and the taxonomic standard was up to 41 years as of March 2021.
3.2 Standardising AMR data analysis
Previously, no dedicated software solution was available to address all aforementioned aspects. To fill this gap, we developed a free, independent, and open-source software solution to cover all those aspects of working with AMR data. The AMR package for R [11] provides functionalities that enable standardised and reproducible workflows from any raw LIS data to results ready to publish, for research and clinical workflows alike. The AMR package for R was developed with a team of contributors from 12 public health organisations in seven countries aiming to be used in any research or clinical setting where (epidemiological) data analysis of microorganisms, AMR, or antimicrobial agents is required. It is independent of any other software solution and was designed to work in any setting, including those with limited computational and financial resources.
With this AMR package, we aimed at providing: (1) tools to simplify AMR data cleaning, transformation, and analysis; (2) methods to easily incorporate (inter)national guidelines; and (3) scientifically reliable reference data, including the aforementioned aspects. The AMR package enables standardised and reproducible AMR data analysis with the application of evidence-based rules (e.g., EUCAST expert rules for intrinsic resistance), the selection of first isolates, the translation of various codes for microorganisms and antimicrobial agents, determination of (multi-)drug-resistant microorganisms, and the calculation of antimicrobial resistance rates, prevalence, and future trends. The AMR package supports all EUCAST MIC/disk diffusion interpretation guidelines from 2011 until 2021 and EUCAST Expert rules versions 3.1 (2016) and 3.2 (2020) [12,13] In addition, the AMR package supports all CLSI MIC/disk diffusion interpretation guidelines from 2011 until 2019 (non-veterinary only). For all mentioned guidelines, files readable for LIS are provided for easy implementation.
As of 30 April 2021, the AMR package for R has been downloaded from 162 countries since its first release in early 2018 (Figure 3.1), according to data from a popular public repository where users can download R packages. After 19 releases, the median number of downloads per release is 2,548 (range: 269-5,050).
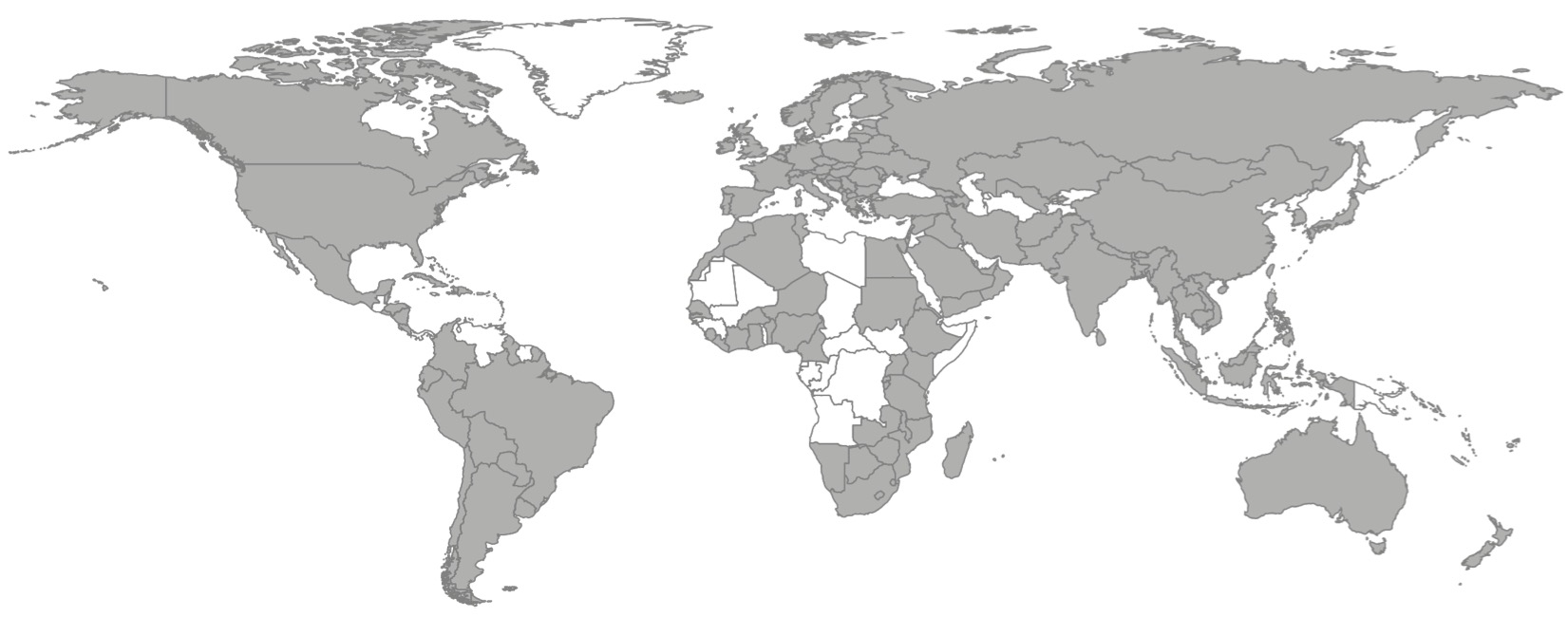
Figure 3.1: Countries (grey, n = 162) with registered downloads of the AMR package for R between March 2018 and April 2021. Sources: cran.rstudio.org and cloud.r-project.org.
A technical validation of the AMR package has been accepted for publication [11]. Additionally, it has been clinically and epidemiologically validated in a tertiary care hospital and across seven clinical microbiology laboratories in the Netherlands [Berends et al., unpublished, see chapter 6 and 7 of this thesis]. Moreover, the AMR package has already been used in several scientific publications that focused on different aspects in the field of AMR [14–17].
3.3 Comparison with existing software methods
Popular statistical software such as SPSS, Stata and SAS, focus on a broad implementation of statistical functions but are proprietary software, disallowing users to freely use, modify, or share the software. This also prohibits extending the software by unaffiliated developers. Since R is free, open software and extendible, users and developers can contribute to the software, to which end the AMR package is a practical example.
Other free software alternatives for AMR data analysis exist, for example WHONET, a free microbiology laboratory database software supported by the WHO [18]. WHONET allows manual data entry from LIS reports and provides AMR interpretation using recent CLSI and EUCAST guidelines with a particular focus on AMR surveillance. Results from WHONET can also be shared to surveillance programs such as the European Antimicrobial Resistance Surveillance Network (EARS-Net) and the WHO Global Antimicrobial Resistance Surveillance System (GLASS). Yet, the latest release, WHONET 2020, does not provide tools for cleaning and transforming data and relies on outdated EUCAST guidelines. Furthermore, we found a lag between the included taxonomic database and the current taxonomic standard of up to 59 years (median 7 years). Another alternative of a free software program is Epi Info which is provided by the United States Centers for Disease Control and Prevention (CDC) and aims at public health practitioners and researchers [19]. While Epi Info provides statistical and epidemiological methods for analysing data, it does not offer tools nor reference data for working with AMR test results or antimicrobial drugs, thus, ruling out the option for dedicated AMR data analysis. With the AMR package for R, an open and dedicated software solution is available that covers all aspects of working with AMR data.
3.4 User feedback
In July 2020, we published a survey on the website created for this package (https://msberends.github.io/AMR) to seek voluntary feedback from package users about user backgrounds and usage of the AMR package. Until December 2020, 18 participants completed the survey. Participants have used the AMR package in Australia, Colombia, Egypt, France, Germany, Haiti, India, Mali, Mexico, the Netherlands, Nigeria, Philippines, Spain, Sweden, and the United Kingdom.
Participants were asked to rate their experience in the statistical programming language R and in using the AMR package on a scale from 1 (not experienced/useful) to 10 (very experienced/useful). The overall experience in R was reported with a median of 7 (range: 4-9)., whereas Ssuit ability for AMR analyses using the AMR package was rated with a median of 9 (range: 6-9). The participants rated the usefulness of the AMR package for their work with a median of 9 (range: 5-9). The convenience of the included software functions was rated with a median of 8 (range: 6-9) and the documentation of the AMR package was rated with a median of 8.5 (range: 7-10). Of all participants, 83% reported more reproducibility of analysis results and, 72% reported more reliable outcomes of AMR analyses (Figure 3.2). Notably, 61% reported new or improved insight into AMR for their institution or region. The AMR package was also used to support clinical decision-making (44%) and for clinical research (28%). Furthermore, 66% reported a faster and streamlined analysis workflow and 39% reported improved communicating analysis results. In 33%, participants started using R more often because of the capabilities that the AMR package provides.
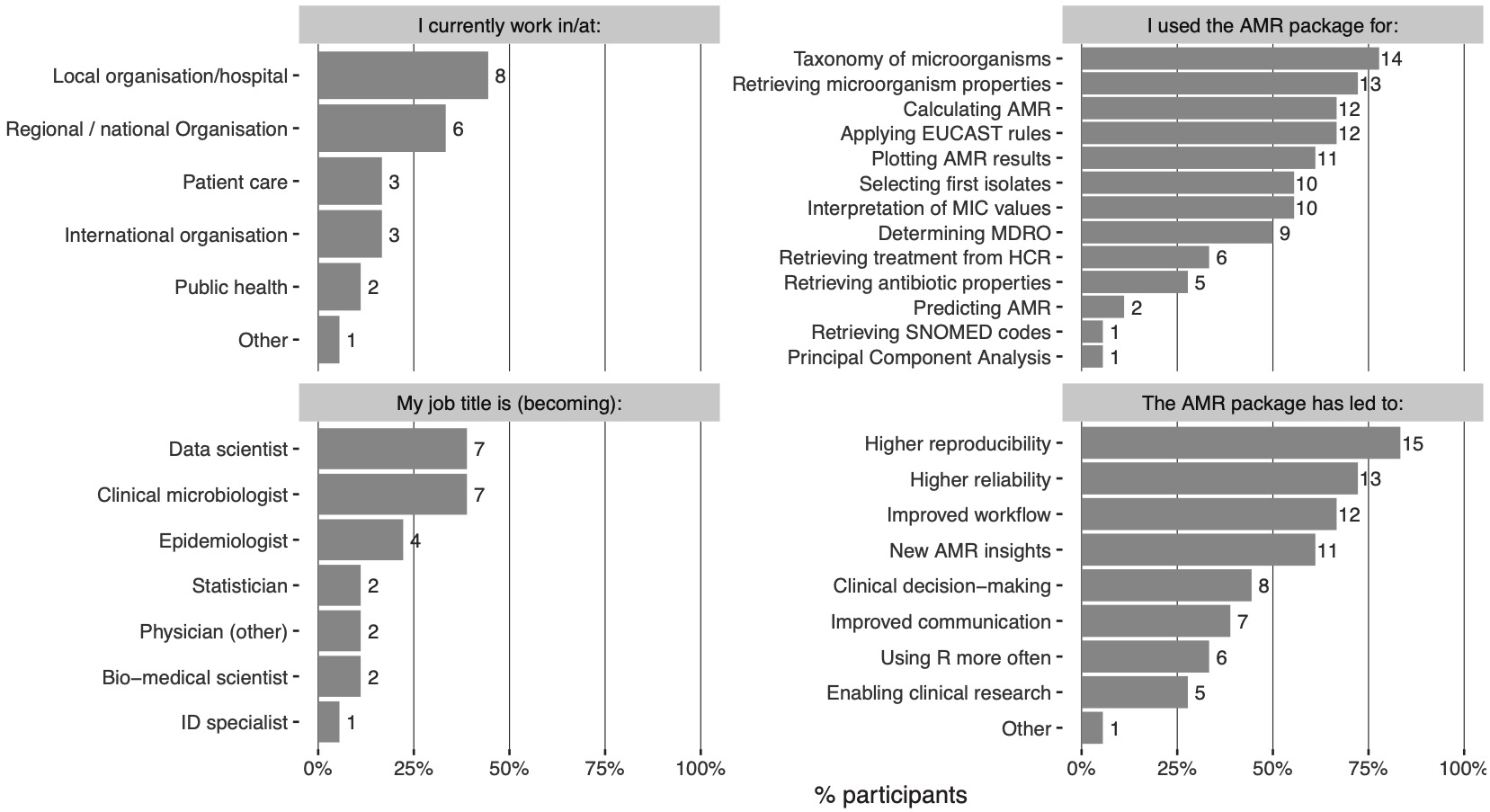
Figure 3.2: The outcome of the survey amongst 18 participants. MIC: minimal inhibitory concentration, MDRO: multidrug-resistant organism, SNOMED: Systematised Nomenclature of Medicine.
Aside from AMR data analysis, most participants (78%) used the AMR package as a reference for the taxonomy of microorganisms. It was also regularly used for interpreting raw MIC and disk diffusion values (56%) and applying EUCAST expert rules (67%). This is in line with the original aims of the AMR package development.
3.5 Conclusion
AMR data analysis is dependent on (inter-)national guidelines and reliable (reference) data on the one hand but constrained by diverse and often inadequate data analysis tools and poor data quality on the other. We aimed to address these dependencies and constraints by introducing the AMR package for R for standardised and reproducible AMR data analyses. Our first insights into the usage and the usability of the AMR package confirm that this package is fulfilling its intended aim. Regional, national, and international organisations already use the AMR package to support clinical decision-making in infection management by gaining new or improved insights into resistance levels. We invite others to make use of our open-source approach and adapt it to their needs. The advantages of sharing open-source software such as the AMR package allow for a collaborative, transparent use and further development that can lead to more standardised analysis processes for AMR data. The flexible open-source design also enables rapid integration of updated guidelines (e.g., new EUCAST breakpoints), and setting-specific adaptations are encouraged. Together, the AMR package for R can thus empower any specialist in the field working with AMR data by providing a comprehensive toolbox of solutions for AMR data analysis.
References
- Limmathurotsakul D, Dunachie S, Fukuda K, Feasey NA, Okeke IN, Holmes AH, et al. Improving the estimation of the global burden of antimicrobial resistant infections. Lancet Infect Dis 2019;3099:1–7. doi:10.1016/S1473-3099(19)30276-2.
- OECD. Stemming the Superbug Tide. Paris: OECD; 2018. doi:10.1787/9789264307599-en.
- Hindler JF, Stelling J. Analysis and Presentation of Cumulative Antibiograms: A New Consensus Guideline from the Clinical and Laboratory Standards Institute. Clin Infect Dis 2007;44:867–73. doi:10.1086/511864.
- Brown D, Canton R, Dubreuil L, Gatermann S, Giske C, MacGowan A, et al. Widespread implementation of EUCAST breakpoints for antibacterial susceptibility testing in Europe. Euro Surveill 2015;20. doi:10.2807/1560-7917.es2015.20.2.21008.
- EUCAST. The European Committee on Antimicrobial Susceptibility Testing. Breakpoint tables for interpretation of MICs and zone diameters. Version 10.0. 2020.
- Kassim A, Omuse G, Premji Z, Revathi G. Comparison of Clinical Laboratory Standards Institute and European Committee on Antimicrobial Susceptibility Testing guidelines for the interpretation of antibiotic susceptibility at a University teaching hospital in Nairobi, Kenya: a cross-sectional stud. Ann Clin Microbiol Antimicrob 2016;15:21. doi:10.1186/s12941-016-0135-3.
- Kassim A, Pflüger V, Premji Z, Daubenberger C, Revathi G. Comparison of biomarker based Matrix Assisted Laser Desorption Ionization-Time of Flight Mass Spectrometry (MALDI-TOF MS) and conventional methods in the identification of clinically relevant bacteria and yeast. BMC Microbiol 2017;17:128. doi:10.1186/s12866-017-1037-z.
- Parte AC, Sardà Carbasse J, Meier-Kolthoff JP, Reimer LC, Göker M. List of Prokaryotic names with Standing in Nomenclature (LPSN) moves to the DSMZ. Int J Syst Evol Microbiol 2020;70:5607–12. doi:10.1099/ijsem.0.004332.
- Tindall BJ, Sutton G, Garrity GM. Enterobacter aerogenes Hormaeche and Edwards 1960 (Approved Lists 1980) and Klebsiella mobilis Bascomb et al. 1971 (Approved Lists 1980) share the same nomenclatural type (ATCC 13048) on the Approved Lists and are homotypic synonyms, with consequences for. Int J Syst Evol Microbiol 2017;67:502–4. doi:10.1099/ijsem.0.001572.
- Alnajar S, Gupta RS. Phylogenomics and comparative genomic studies delineate six main clades within the family Enterobacteriaceae and support the reclassification of several polyphyletic members of the family. Infect Genet Evol 2017;54:108–27. doi:10.1016/j.meegid.2017.06.024.
- Berends MS, Luz CF, Friedrich AW, Sinha BNM, Albers CJ, Glasner C. AMR - An R Package for Working with Antimicrobial Resistance Data. J Stat Softw 2021;(in press). doi:https://doi.org/10.1101/810622.
- EUCAST. The European Committee on Antimicrobial Susceptibility Testing. Intrinsic Resistance and Exceptional Phenotypes. Version 3.1. 2016.
- EUCAST. The European Committee on Antimicrobial Susceptibility Testing. Intrinsic Resistance and Exceptional Phenotypes. Version 3.2. 2020.
- Le Guern R, Titécat M, Loïez C, Duployez C, Wallet F, Dessein R. Comparison of time-to-positivity between two blood culture systems: a detailed analysis down to the genus-level. Eur J Clin Microbiol Infect Dis 2021. doi:10.1007/s10096-021-04175-9.
- Dutey-Magni PF, Gill MJ, McNulty D, Sohal G, Hayward A, Shallcross L, et al. Feasibility study of hospital antimicrobial stewardship analytics using electronic health records. JAC-Antimicrobial Resist 2021;3. doi:10.1093/jacamr/dlab018.
- N. Tenea G, Jarrin-V P, Yepez L. Microbiota of Wild Fruits from the Amazon Region of Ecuador: Linking Diversity and Functional Potential of Lactic Acid Bacteria with Their Origin. Ecosyst. Biodivers. Amaz., IntechOpen; 2021. doi:10.5772/intechopen.94179.
- Kim S, Yoo SJ, Chang J. Importance of Susceptibility Rate of ‘the First’ Isolate: Evidence of Real-World Data. Medicina (B Aires) 2020;56:507. doi:10.3390/medicina56100507.
- World Health Organization. WHONET 2020. https://whonet.org (accessed May 20, 2021).
- Centers for Disease Control and Prevention (CDC). Epi Info (TM) 2020. https://www.cdc.gov/epiinfo/index.html (accessed May 20, 2021).